Python程序设计-B站热门视频数据可视化
项目介绍
本项目为《Python程序设计》课程的期末作业,聚焦于对B站(哔哩哔哩)热门视频榜单数据的抓取与可视化分析。通过使用 Python 编写爬虫脚本,获取指定时间段内的热门视频信息(包括标题、分区、播放量、点赞率、投币率、弹幕数等),并借助 ECharts 等前端可视化工具进行数据呈现。
本网页所展示数据为2025年6月5日爬取。
Web可视化
请直接访问以下链接体验~(因网页尺寸被压缩,若弹窗右上角关闭按钮识别困难可点击周围空白界面退出)
程序运行视频解说
程序运行图文解说
项目概述
本项目旨在从 Bilibili 获取热门视频数据,进行数据处理、分析,并通过交互式网页图表进行可视化展示。
示例数据获取时间为 6 月 5 日 17 时。
一、程序构思
目标:
- 获取 Bilibili 全站热门排行榜 Top100 的视频数据。
- 对数据进行清洗和处理。
- 进行多维度数据分析,例如:
- 各分区的视频数量分布。
- 不同分区的平均播放量、点赞数等。
- 播放量、点赞数、投币数之间的关系。
- 视频时长分布。
- 视频发布时间规律。
- 通过网页实现交互式的数据可视化,方便用户查看和探索数据。
技术选型:
后端 / 数据处理:
- 编程语言:Python
- 网络请求:
requests库 - 数据处理与分析:
pandas库 - 静态图表生成:
matplotlib库
前端 / 可视化:
- HTML, CSS, JavaScript
- 图表库:
ECharts.js
核心功能模块:
- 数据爬取模块(
crawler.py) - 数据分析模块(
analysis.py,用于生成静态图表) - 数据存储模块(Excel 文件
bilibili_hot100.xlsx,JSON 文件bilibili_hot100.json) - 交互式可视化模块(
interactive_bilibili_hot_100.html)
- 数据爬取模块(
实现过程
1. 数据获取(crawler.py)
- 使用
requests,pandas,datetime库 - 模拟浏览器访问 B站 API,防反爬
- 获取 Top100 榜单数据,保存为 Excel / JSON
实现步骤:
使用
requests.get()方法,携带必要的headers,向 B站 API 发送请求获取 API 返回的 JSON 数据
解析 JSON 数据,提取字段,如:排名、标题、BV号、UP主、分区、播放数、点赞数、投币数等
使用
pandas构建 DataFrame保存为 Excel 文件:
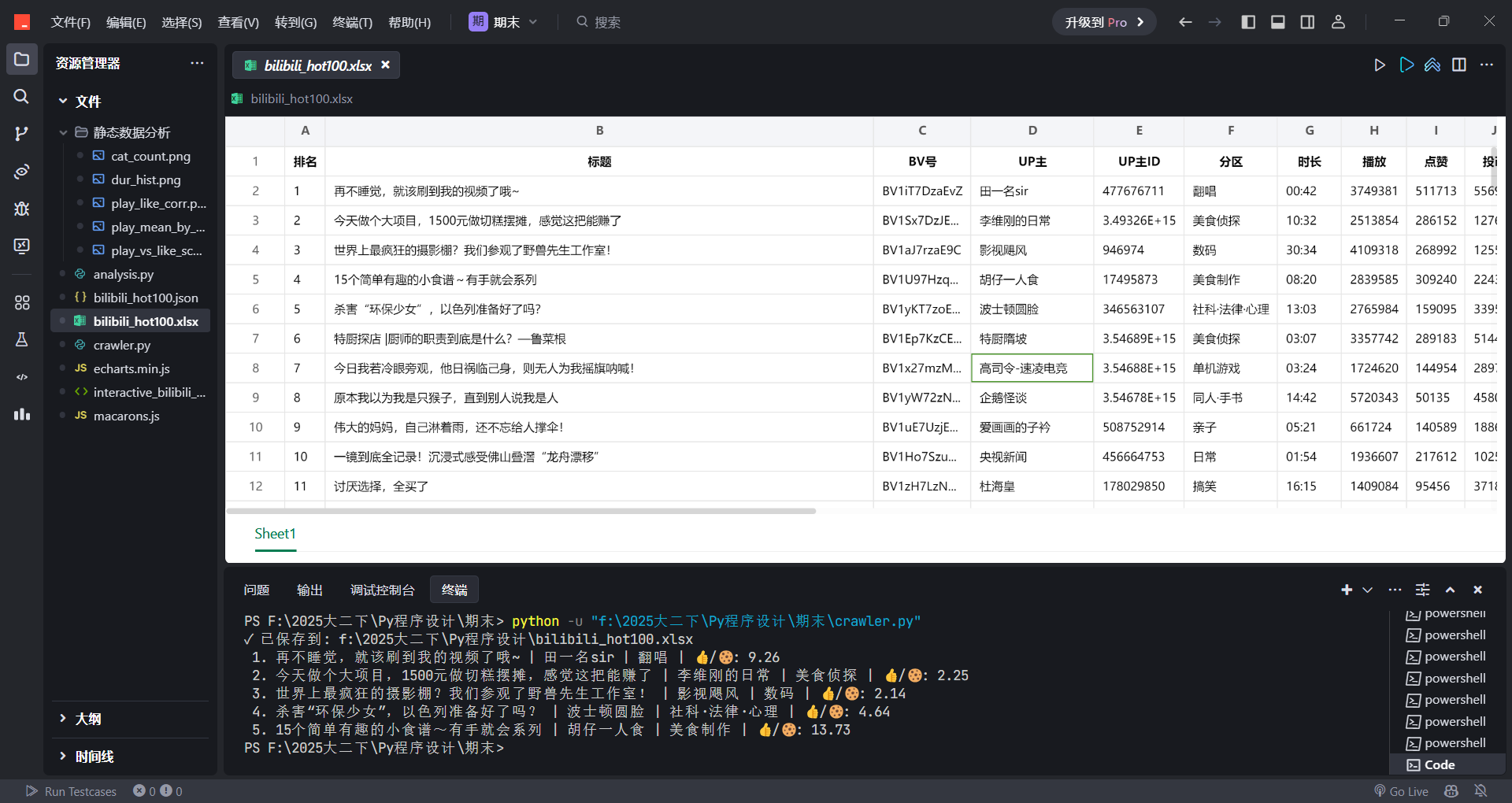
同时保存为 JSON 文件(如
bilibili_hot100.json)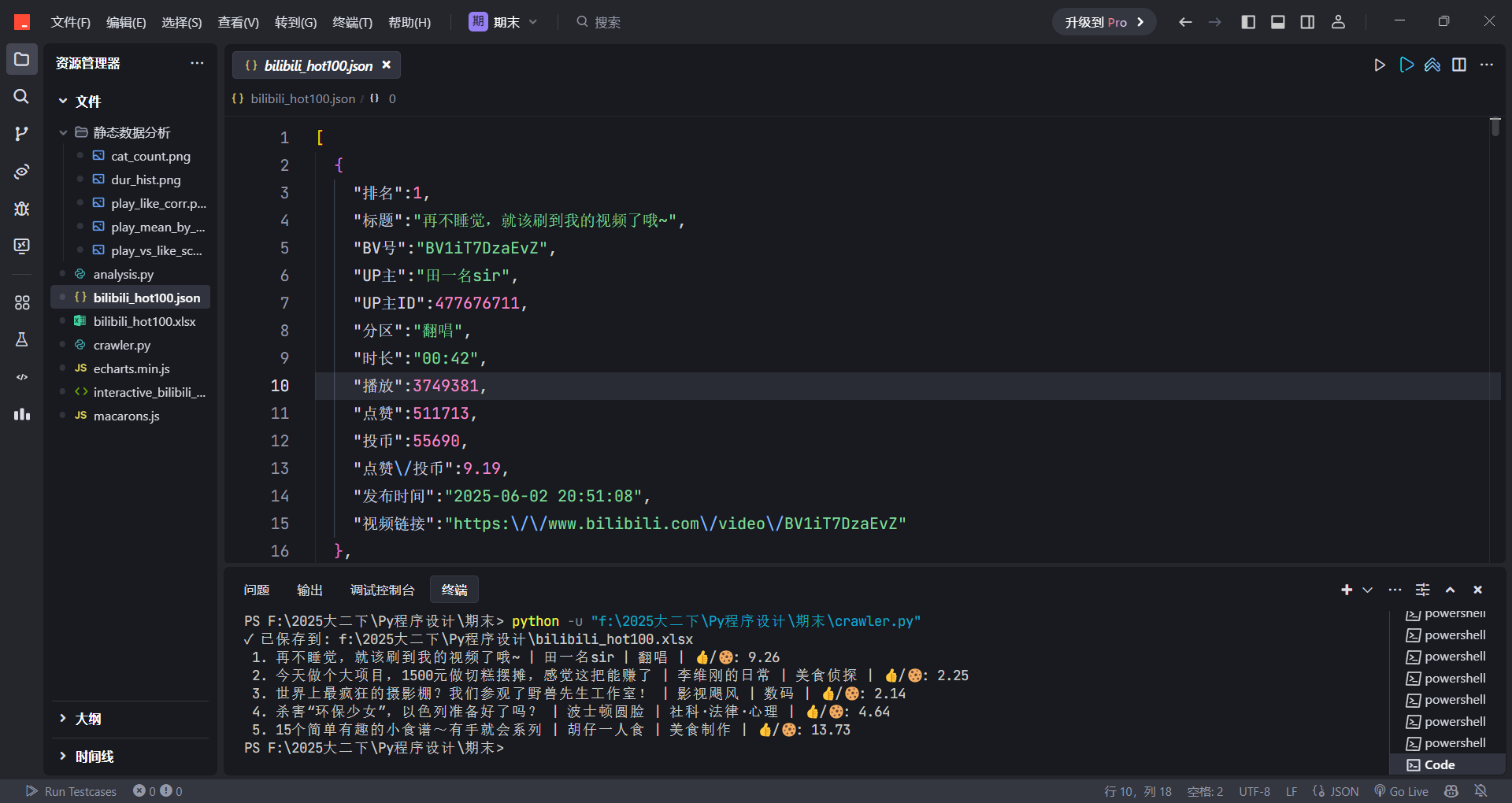
2. 数据分析与静态图表生成(analysis.py)
- 使用
pandas,matplotlib.pyplot,pathlib - 生成统计图表用于初步分析
示例图表:
cat_count.png:分区出现次数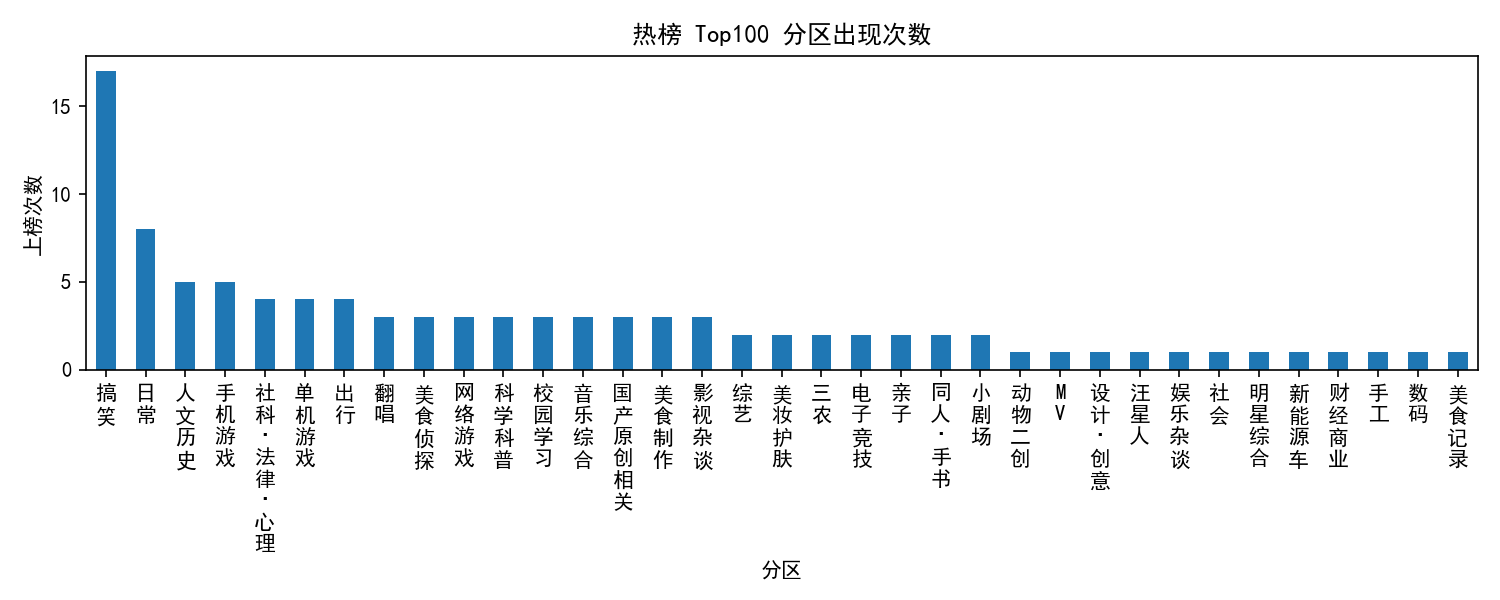
dur_hist.png:视频时长分布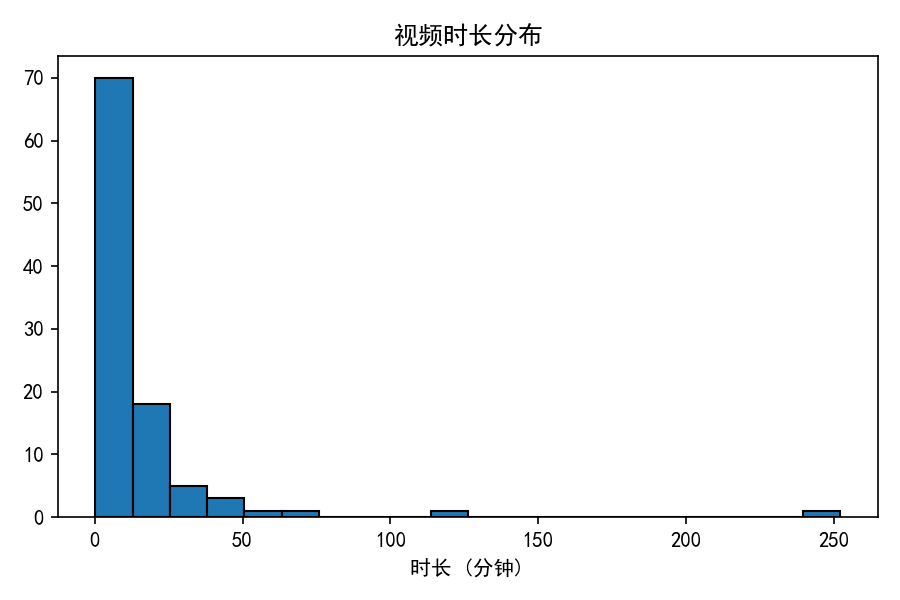
play_like_corr.png:播放量与点赞数热力图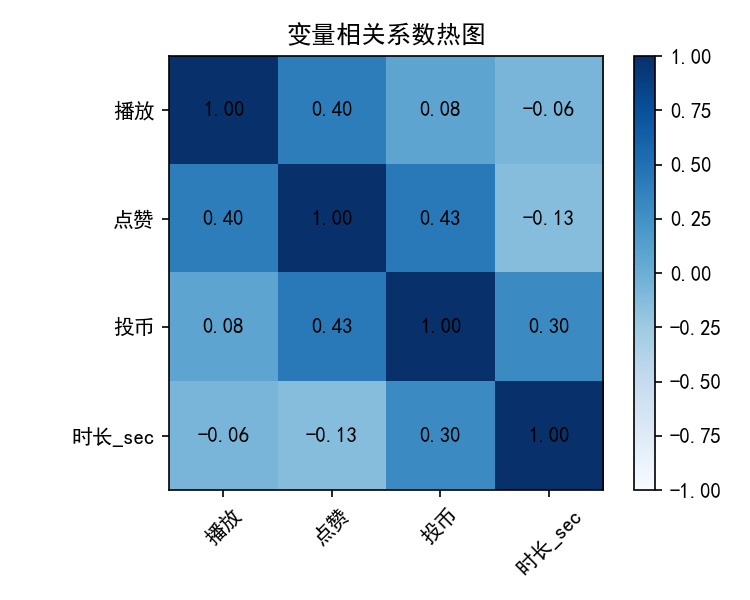
play_mean_by_cat.png:分区平均播放量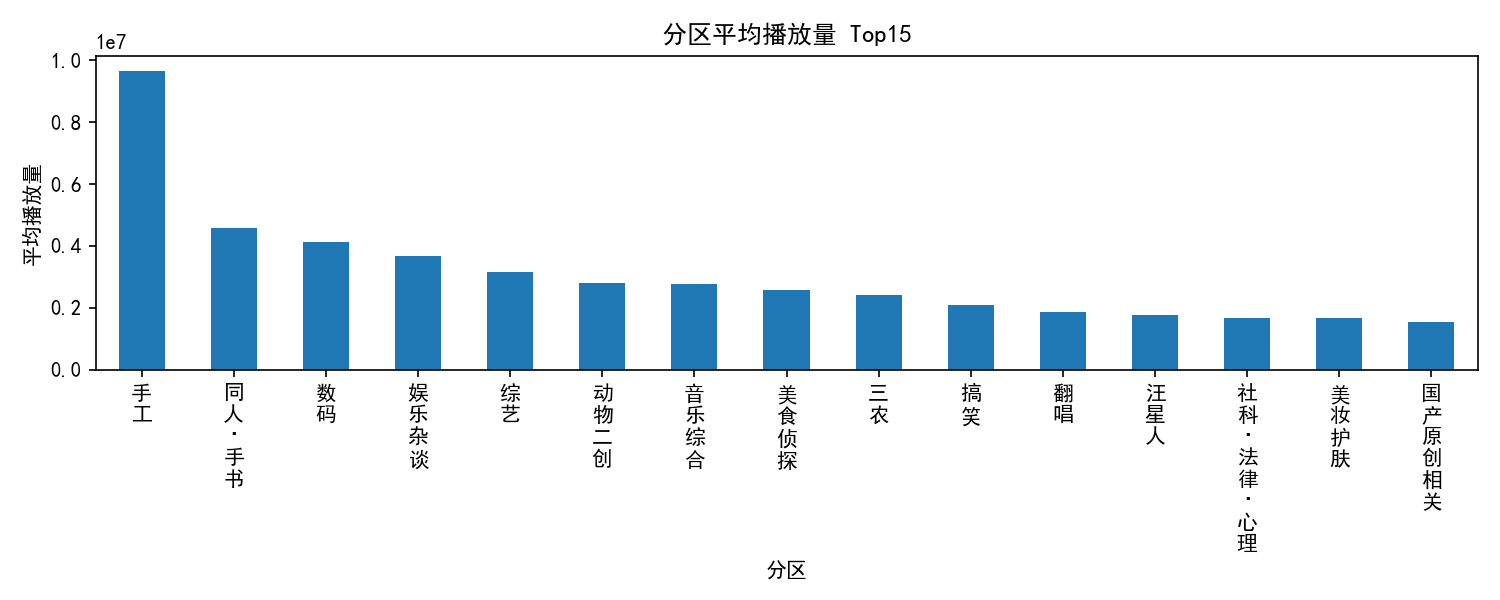
play_vs_like_scatter.png:播放量 Vs 点赞量气泡图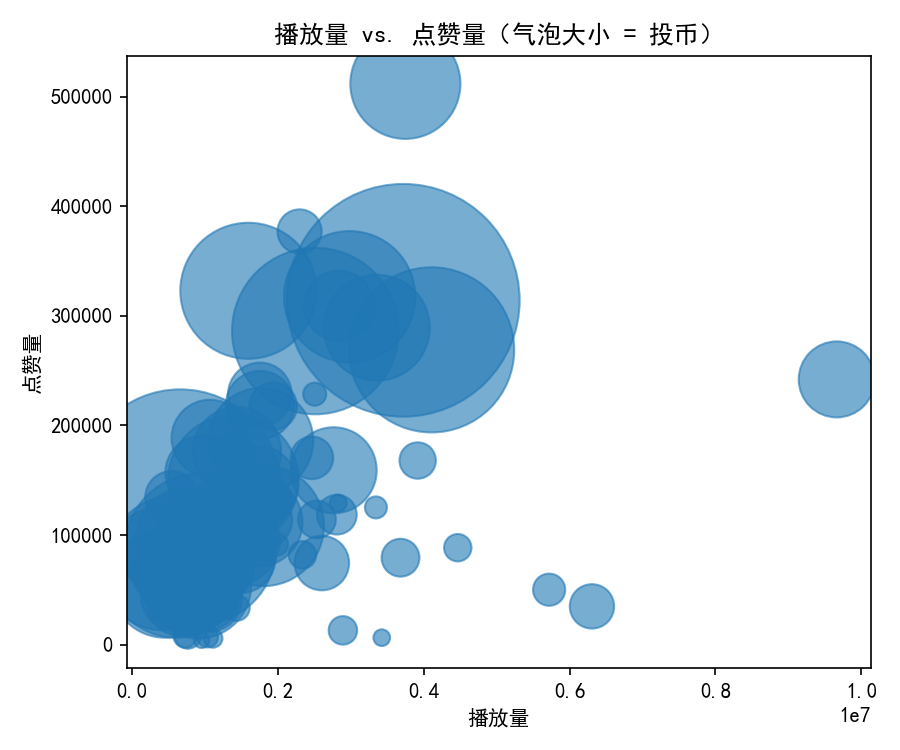
3. 交互式 Web 可视化(interactive_bilibili_hot_100.html)
HTML结构与引入
- 引入
echarts.min.js和macarons.js主题 <title>Bilibili 热榜 Top100 · 交互数据分析</title>- 包含基本 CSS 样式
交互按钮设计:
- 按钮控制切换不同图表(分区饼图、Top10 等)
- 使用
data-chart属性做事件绑定
数据注入与图表初始化:
- 使用 JS 常量
const DATA = {...}注入 JSON 数据 - ECharts 渲染图表,根据按钮动态切换视图
网页呈现效果示例:
柱状图展示分区数量:
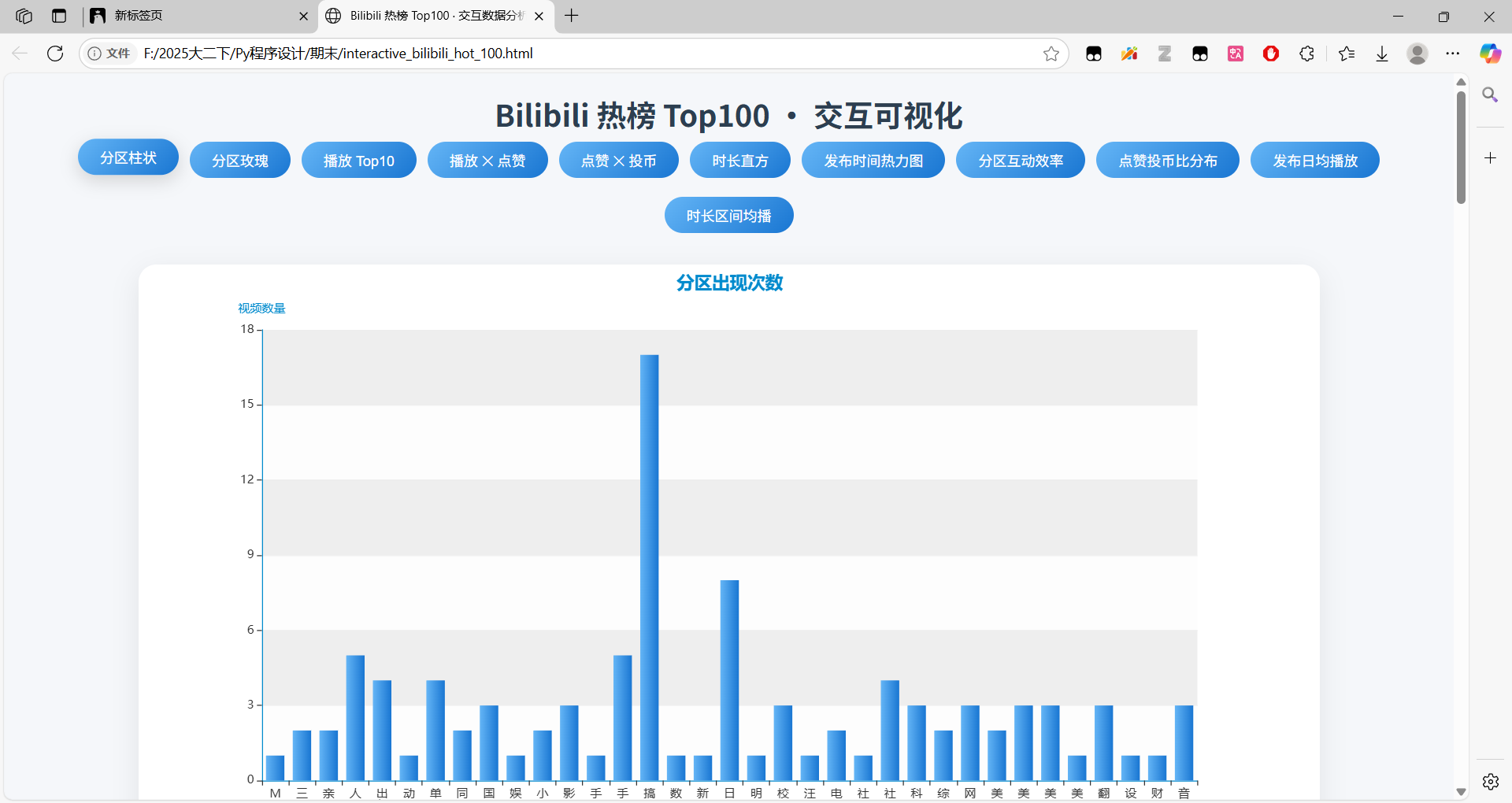
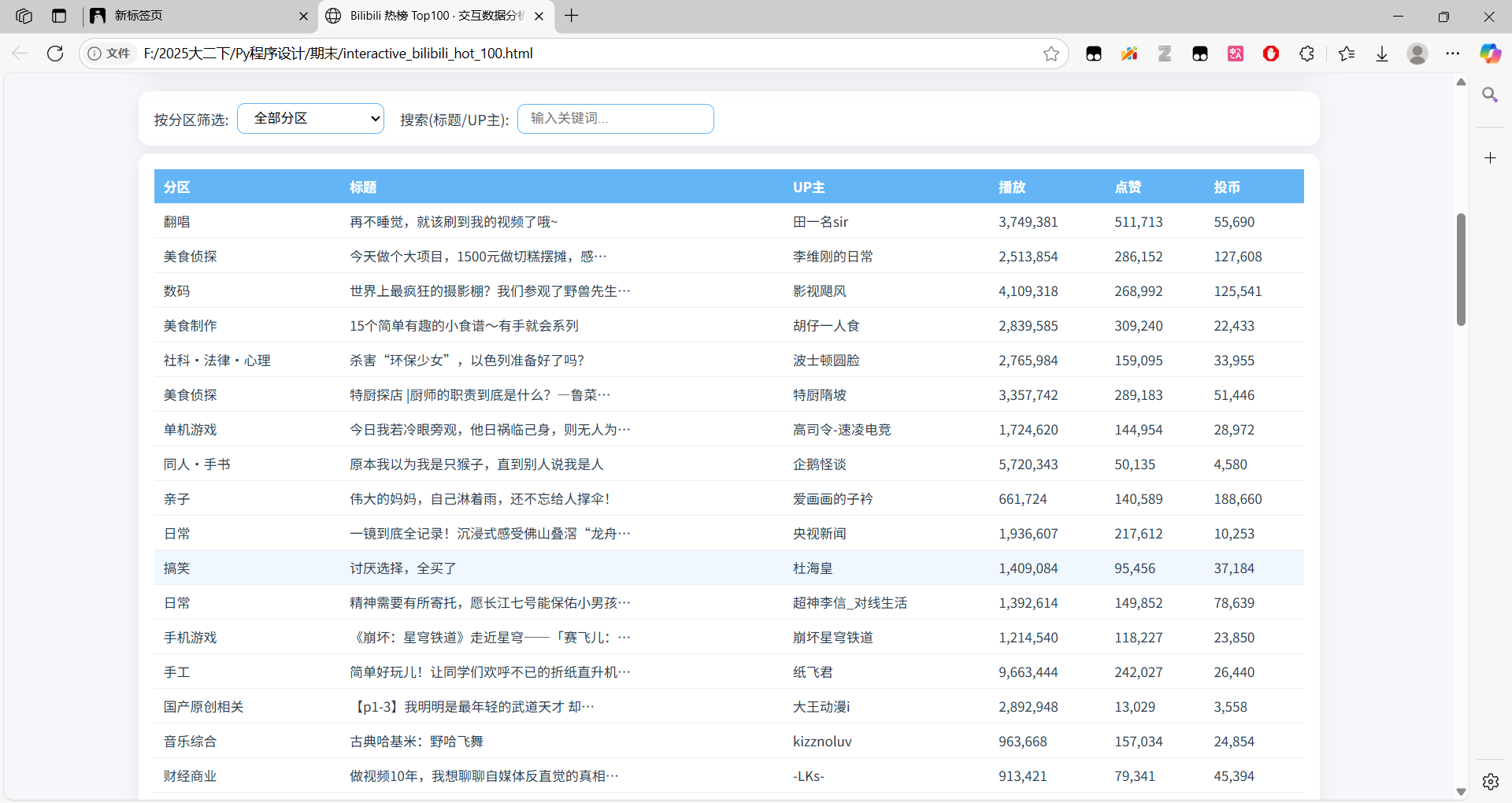
原始数据表格视图 + 筛选功能:
总结
本项目通过 Python 爬虫获取 B站热榜数据,结合 pandas 和 matplotlib 进行初步分析,最终使用 ECharts 构建交互式网页进行数据可视化展示。
项目覆盖了从爬取、清洗、分析到可视化的完整流程,展示了数据驱动内容分析的应用价值。